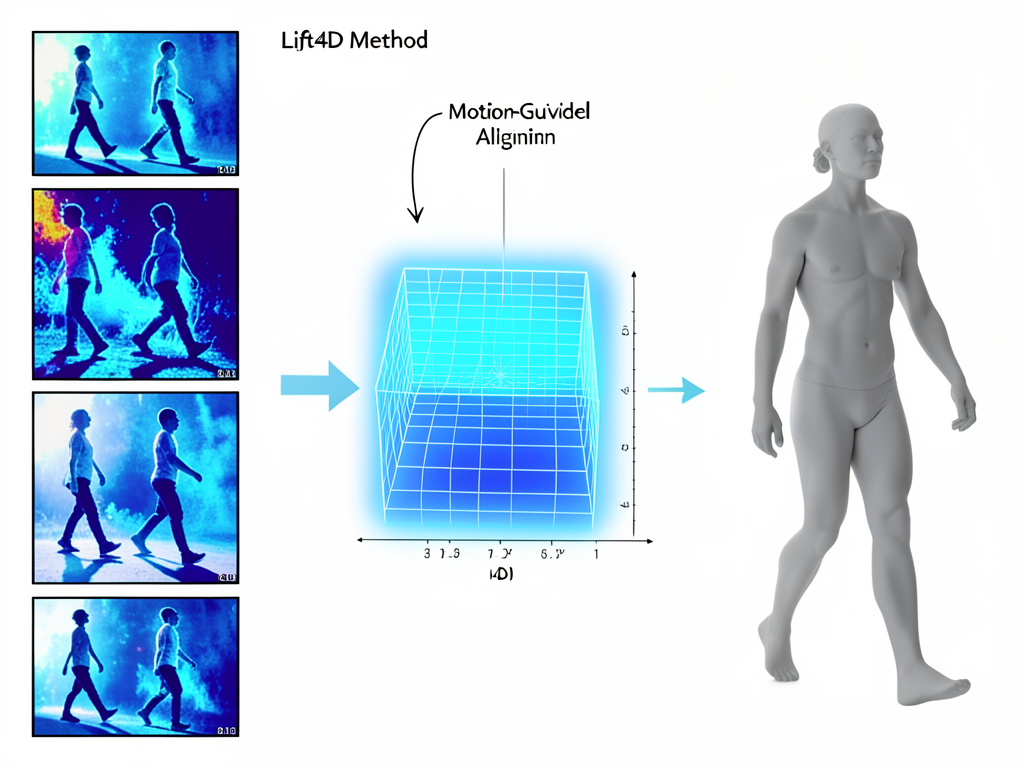
Researchers have introduced Lift4D, a technique that improves 4D reconstruction from a single camera view by harmonizing 3D estimates across time. The method addresses a key limitation in computer vision: maintaining temporal coherence when reconstructing dynamic scenes from monocular video.
The Challenge of Consistent 4D Reconstruction
Most single-view 3D reconstruction methods treat each video frame independently. This independence often leads to depth inconsistencies across frames, causing jitter and drift in the resulting 4D model. Such artifacts have prevented practical use in applications where smooth, real-world motion is essential. Lift4D tackles this by introducing a harmonization mechanism that enforces temporal consistency.
How Lift4D Works
Lift4D builds on implicit neural representations and motion cues to align depth estimates across a sequence. Instead of optimizing each frame separately, the method jointly learns a continuous 4D field that respects both spatial accuracy and temporal smoothness.
Why This Matters
The ability to produce reliable 4D reconstructions from ordinary video has wide-ranging implications. Autonomous robots can better track moving objects using a single camera. AR and VR systems can place virtual content that interacts realistically with real-world motion. Content creators can extract dynamic 3D assets without expensive multi-camera rigs.
Current methods often break under occlusions or fast motion. Lift4D's harmonization strategy shows robustness in these challenging conditions, moving toward real-world deployment where controlled environments are not guaranteed.