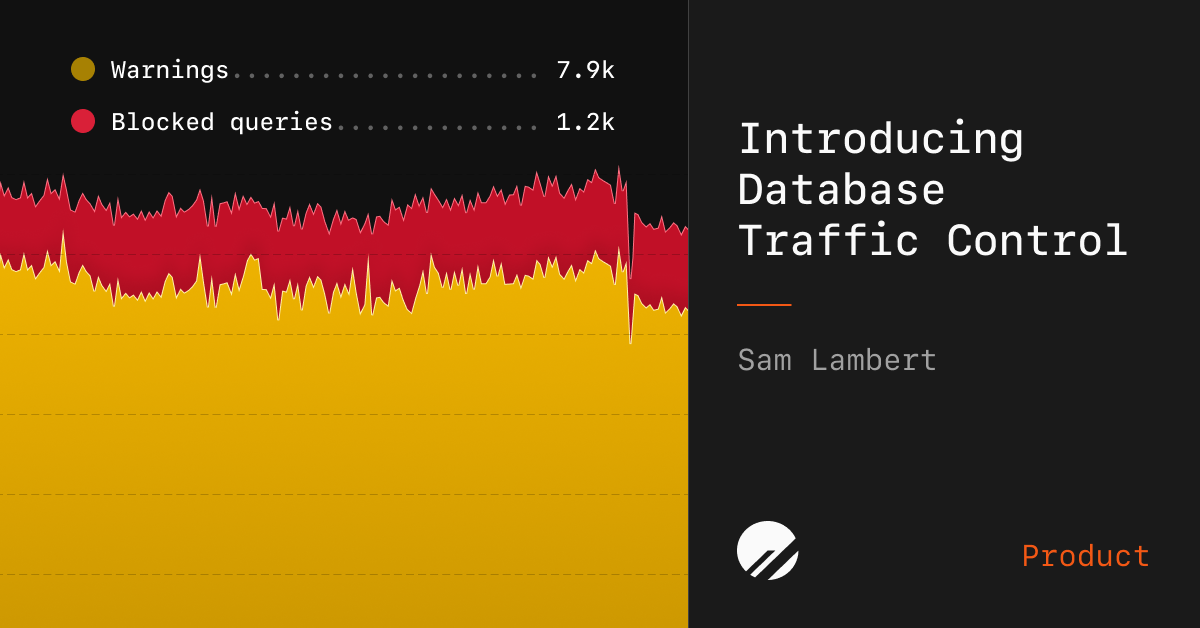
For years developers building distributed applications have faced a painful trade-off between consistency and performance. A growing number of engineers now argue that Postgres transactions offer a way out of that dilemma turning what many saw as a bottleneck into a genuine superpower for distributed system design.
The Transaction Advantage
Postgres provides atomicity isolation and durability through its well-tested MVCC engine. Developers traditionally used these features only within one database instance but recent patterns extend them across service boundaries using foreign data wrappers logical replication and careful schema design.
The key insight is that a single Postgres transaction can atomically update multiple tables representing different bounded contexts within an application. When combined with features like SERIALIZABLE isolation developers can guarantee global consistency without introducing separate coordination services.
Why This Matters
The shift toward microservices has forced teams to choose between strong consistency and system simplicity. Many adopt eventual consistency with sagas or event sourcing which adds operational complexity and debugging difficulty.
Postgres transactions change this calculus by letting teams keep strong consistency while still decomposing their applications into independent services. This reduces the need for specialized distributed databases like CockroachDB or Spanner for many workloads lowering infrastructure costs and cognitive load on developers.
The real-world impact is significant. Teams can build reliable financial systems inventory management platforms and collaborative editing tools using familiar SQL semantics rather than learning new consistency models.
Real-World Patterns
Several proven patterns demonstrate how to apply this approach effectively:
The Limits of This Approach
Relying on a single Postgres instance as the transaction coordinator introduces clear limitations. The database becomes a single point of failure and its write throughput caps overall system scalability.
Citus extends Postgres with sharding but cross-shard transactions incur network overhead. Patroni provides high availability through automatic failover but failover events can abort in-flight transactions requiring application-level retry logic.
For workloads requiring global multi-region consistency specialized databases like Google Spanner remain necessary. However many applications do not need that level of distribution making the single-node approach viable for most teams.
A Practical Path Forward
The resurgence of interest in Postgres as a distributed systems foundation reflects broader industry trends toward simpler infrastructure. Rather than assembling complex stacks of message brokers caches and consensus algorithms teams can start with what they already know.
Postgres ACID transactions provide a proven foundation for building reliable distributed applications when combined with careful schema design and appropriate scaling strategies like read replicas connection pooling and partitioning.
The lesson is clear sometimes the most powerful tool for distributed systems is not new technology but deeper understanding of existing capabilities.